Метод AdvancedFilter
Метод AdvancedFilter (расширенный фильтр) является более мощным и универсальным средством фильтрации, чем метод AutoFilter. Он позволяет использовать фильтрацию по большему числу критериев, причем допустимо применение критериев, включающих формулы. Кроме того, метод AdvancedFilter позволяет фильтровать список с выводом результата фильтрации как непосредственно на том месте, где он расположен, так и в новое специфицированное место. Вручную метод запускается посредством выбора команды Данные, Фильтр, Расширенный фильтр (Data, Filter, Advanced Filter).
Синтаксис:
Объект.AdvancedFilter(Action, CriteriaRange, CopyToRange, Unique)
Аргументы:
|
Action |
Допустимые значения:: xiFilterinPiace (фильтровать список на месте) и xiFiiterCopy (скопировать результат на новое место) | ||||
|
CriteriaRange |
Ссылка на диапазон с критериями | ||||
|
CopyToRange |
Если параметр Action принимает значение xiFiiter-сору, то он указывает диапазон, куда будет копироваться результат фильтрации | ||||
|
Unique |
Допустимые значения True (отбирается только один вариант записи из многократно встречающихся в списке) и False (отбираются все встречающиеся записи) | ||||
Приведем соответствие между аргументами метода Advanced Filter и выполнением команды Данные, Фильтр, Расширенный фильтр (Data, Filter, Advanced Filter) при фильтрации базы данных регистрации туристов.
|
Шаг 1 |
Выделяем диапазон AI : G13, содержащий фильтруемую базу данных. (рис. 3.8). Прежде чем выбирать команду Данные, Фильтр, Расширенный фильтр (Data, Filter, Advanced Filter), необходимовыполнить предварительные построения по созданию диапазона критериев. Верхняя строка диапазона критериев должна содержать заголовки полей фильтруемых данных. При этом нет необходимости включать все заголовки и сохранять их порядок. В диапазон критериев также должны входить строки с условиями фильтрации. Все условия в диапазоне критериев, записанные под заголовком поля, относятся к этому полю. При применении расширенного фильтра допустима запись нескольких условий в строке диапазона критериев. Условия, расположенные в одной строке, рассматриваются как условия, объединенные логической операцией и (And) , а расположенные в нескольких — логической операцией или (Or) В данном случае под диапазон критериев отведем диапазон A16:G17. В базе данных выберем записи обо всех мужчинах, которые едут в Лондон. С этой целью в ячейку С17 диапазона критериев введем значение муж, а в ячейку D17— Лондон. | ||||

Рис. 3.8. Фильтруемый список
Шаг 2 |
Выберем команду Данные, Фильтр, Расширенный фильтр (Data, Filter, Advanced Filter). Появится диалоговое окно Расширенный фильтр (Advanced Filter) (рис. 3.9). Переключатели группы Обработка (Action) определяют, где будут располагаться отфильтрованные данные. В рассматриваемом случае не будем фильтровать список на месте, а скопируем результат фильтрации в другое место. Поэтому выберем переключатель скопировать результат в другое место (Copy to Another Location). У метода AdvancedFilter за выбор местоположения результата фильтрации отвечает аргумент Action. При данном выборе переключателя аргументу Action присваивается значение xlFilterCopy. В поле Исходный диапазон (List Range) вводится ссылка на диапазон с фильтруемыми данными — AI : G13. П В поле Диапазон условий (Criteria Range) вводится ссылка на диапазон с критериями — A16:G17. У метода AdvancedFilter определение диапазона с критериями осуществляется с помощью аргумента criteriaRange. Поэтому ему присваивается диапазон Range ("A16:G17") . В поле Поместить результат в диапазон (Copy to) дается ссылка на диапазон назначения. В данном случае A19:G19. Переменной в методе AdvancedFiiter, отвечающей за диапазон назначения, является CopyToRange. Поэтому ей надо присвоить диапазон Range ("A19:G19"). Флажок Только уникальные записи (Unique Records Only) определяет, будут ли отображаться все отфильтрованные записи или только по одной из всех одинаковых записей, удовлетворяющих критерию. В данном случае снимем флажок Только уникальные записи (Unique Records Only). Поэтому переменной unique присваиваем значение False. Подытожим все присвоения значений аргументов: Range ( "A1 : G13" ) .AdvancedFiiter Action :=xlFilterCopy, CriteriaRange : =Range ("A16:G17" ) , CopyToRange : =Range ( " Al 9 : Gl 9 " ) , Unique : =False |
||

Рис. З.9. Диалоговое окно Расширенный фильтр
ШагЗ |
Нажатие кнопки OK приводит к фильтрации данных по указанному критерию. |
||
Метод AutoFill
Метод AutoFill (автозаполнение) автоматически заполняет ячейки диапазона элементами последовательности. Метод AutoFill отличается от метода DataSeries тем, что явно указывается диапазон, в котором будет располагаться прогрессия. Вручную этот метод эквивалентен расположению указателя мыши на маркере заполнения выделенного диапазона (в который введены значения, порождающие создаваемую последовательность) и протаскивании маркера заполнения вдоль диапазона, в котором будет располагаться создаваемая последовательность.
Синтаксис:
Объект.AutoFill(destination, type)
Аргументы:
|
Объект |
Диапазон, с которого начинается заполнение | ||||
|
destination |
Диапазон, который заполняется | ||||
|
type |
Допустимые значения: xiFiilDefauit, xlFillSeries, xlFillCopy, xlFillFormats, xlFillValues, xlFillDays, xlFillWeekdays, xlFillMonths, xlFillYears, xlLinearTrend, xlGrowthTrend. По умолчанию xlFillDefault | ||||
Приведем соответствие между аргументами метода AutoFill и построением последовательности на рабочем листе вручную на примере построения арифметической прогрессии по двум ее первым членам.
|
Шаг 1 |
В ячейку AI введите первый член профессии, например 5. В ячейку А2 введите второй член профессии, например 7. Выделите диапазон А1:А2, содержащий два первых члена арифметической профессии. Расположите указатель мыши над маркером заполнения выделенного диапазона так, чтобы он превратился в черный крест (рис. 3.3). | ||||

Рис. 3.3. Выделение двух первых членов прогрессии
|
Шаг 2 |
При нажатой левой кнопке мыши, протащите маркер заполнения вниз по столбцу так, чтобы создать требуемую последовательность. В данном случае протащим маркер заполнения так, чтобы создать последовательность в диапазоне А1:А5 (рис. 3.4). Тот же результат получается, если аргументу Destination метода AutoFill присваивается Range ("Ai:A5"), аргументу туре присваивается xiFiiiDefauit, а метод применяется к диапазону Range ("A1:A2") . Таким образом, имеем: Range ( "Al :A2") .AutoFill Destination: =Range ( "Al : A5" ),_ Type : =xlFillDef ault | ||||

Рис. З.4. Построенная прогрессия
Метод AutoFilter
Метод AutoFilter (автофильтр) представляет собой простой способ запроса и фильтрации данных на рабочем листе. Если AutoFilter активизирован, то каждый заголовок поля выделенного диапазона данных превращается в поле с раскрывающимся списком. Выбирая запрос на вывод данных в поле с раскрывающимся списком, вы осуществляете вывод только тех записей, которые удовлетворяют указанным условиям. Поле с раскрывающимся списком содержит следующие типы условий: Все (АИ), Первые десять (Тор 10), Условие (Custom), конкретный элемент данных, Пустые (Blanks) и Непустые (NohBlanks). Вручную метод запускается посредством выбора команды Данные, Фильтр, Автофильтр (Data, Filter, AutoFilter).
При применении метода AutoFilter допустимы два синтаксиса.
Синтаксис 1:
Объект.AutoFilter
В этом случае метод AutoFilter выбирает или отменяет команду Данные, Фильтр, Автофильтр (Data, Filter, AutoFilter), примененную к диапазону, заданному в аргументе объект.
Синтаксис 2:
Объект.AutoFilter(field, criterial, operator, criteria2)
В этом случае метод AutoFilter выполняет команду Данные, Фильтр, Автофильтр (Data, Filter, AutoFilter) по критериям, указанным в аргументе.
Аргументы:
|
Объект |
Диапазон | ||||
|
field |
Целое, указывающее поле, в котором производится фильтрация данных | ||||
|
criterial И criteria2 |
Задают два возможных условия фильтрации поля. Допускается использование строковой постоянной, например 101, и знаков отношений >, < ,>=, <=, =, <> | ||||
|
operator |
Допустимые значения: П xiAnd (логическое объединение первого и второго критериев) П xior (логическое сложение первого и второго критериев) П xiTopioitems (для показа первых десяти элементов поля) | ||||
При работе с фильтрами полезны метод ShowAllData и свойства FilterMode и AutoFilterMode.
|
Метод ShowAllData |
Показывает все отфильтрованные и неотфильтрованные строки рабочего листа | ||||
|
Свойства FilterMode |
Допустимые значения: True (если на рабочем листе имеются отфильтрованные данные со скрытыми строками), False (в противном случае) | ||||
|
Свойство AutoFilterMode |
Допустимые значения: True (если на рабочем листе выведены раскрывающиеся списки метода AutoFilter), False (в противном случае) | ||||
Приведем соответствие между аргументами метода AutoFilter и выполнением команды Данные, Фильтр, Автофильтр (Data, Filter, AutoFilter) при фильтрации базы данных регистрации туристов.
Шаг 1 |
Выделяем диапазон A1 = E1, содержащий заголовки полей базы данных. Выберем команду Данные, Фильтр, Автофильтр (Data, Filter, AutoFilter). В результате в заголовках полей появятся раскрывающиеся списки (рис. 3.5). В этих раскрывающихся списках предлагаются варианты допустимой фильтрации. В методе AutoFilter за диапазон с названиями полей отвечает объект, к которому применяется метод. В данном случае метод AutoFilter надо Применить к диапазону Range ("A1: E1") . |
||

Рис. 3.5. Раскрывающиеся списки метода AutoFilter
Шаг 2(а) |
Отфильтруем в базе данных, например, только данные о клиентах, направляющихся в афины (рис. 3.6). С этой целью в раскрывающемся списке поля Направление тура выберем Афины. В результате на рабочем листе будут выведены только записи, соответствующие турам в Афины. В методе AutoFilter за выбор поля, в котором производится фильтрация, отвечает аргумент Field. В данном Случае для выбора поля Направление тура аргументу Field надо присвоить значение 4. За критерии, покоторым производится фильтрация, отвечают аргументы criteria1 и criteria2. В данном случае фильтрация производилась по одному критерию — АФИНЫ, поэтому только аргументу criterial надо присвоить значение АФИНЫ. Таким образом, имеем: Range ( "Al : El " ) . Select Selection. AutoFilte r Selection. AutoFilter Field:=4, Criteria1 : ="Афины" |
||
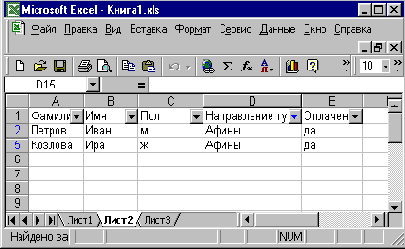
Рис. 3.6. Фильтрация списка по критерию Афины

Рис. 3.7. Диалоговое окно Пользовательский автофильтр
Шаг 2(b) |
При фильтрации по условию появляется диалоговое окно Пользовательский автофильтр (Custom AutoFilter), позволяющее отфильтровать записи по двум критериям в одном поле (рис. 3.7). Например, отфильтруем все туры в Афины и Берлин. В методе AutoFilter это соответствует присвоению аргументам Сriterial и criteria2 значений Афины и Берлин соответственно, а аргументу operator — значения хlor, т. к. будут отображаться либо туры в Афины, либо в Берлин . Таким образом, имеем: Range ("A1:E1") .Select Select ion. AutoFilter Selection. AutoFilter Field:=4, Criterial : ="=Афины" , Operator : =xlOr , Criteria2 :="=Берлин" |
||
Метод Consolidate
Метод consolidate (консолидация) применяется для объединения данных из нескольких диапазонов в одну итоговую таблицу, которые могут находиться на различных рабочих листах. Этот метод позволяет подвести итоги и обобщить однородные данные, размещенные в нескольких диапазонах. Вручную метод consolidate выполняется с помощью команды Данные, Консолидация (Data, Consolidate).
Синтаксис:
Объект.Consolidate(Sources, Function, TopRow, LeftColumn, CreateLinks)
Аргументы:
|
Объект |
Диацазон, где будет построена итоговая таблица | ||||
|
Sources |
Массив ссылок в R1C1 -формате на диапазоны, по которым строится итоговая таблица. Ссылки должны содержать полные имена диапазонов с указанием имен рабочих листов, на которых они расположены | ||||
|
Function |
Функция, на основе которой строится итоговая таблица. Допустимые значения: xlAverage (среднее) xlcount (количество значений) xlCountNums (количество чисел) xlMax (максимум) xlMin (минимум) xlProduct (произведение) xlstDev (несмещенная дисперсия) xlstDevP (смещенная дисперсия) xlSum (сумма) О xlvar (несмещенное отклонение) xlVarp (смещенное отклонение) | ||||
|
TopRow |
Допустимые значения: True (консолидация основывается на заголовках столбцов, консолидируемых диапазонов) и False (в противном случае) | ||||
|
LeftColumn |
Допустимые значения: True (консолидация основывается на заголовках строк, консолидируемых диапазонов) и False (в противном случае) Если консолидация происходит по расположению, то можно снять флажки подписи верхней строки (Top Row) и значения левого столбца (Left Column). Эти флажки должны быть установлены, если консолидация происходит согласно заголовкам строк и столбцов. В данном случае установим эти два флажка. Флажок Создавать связи с исходными данными (Create Links to Source Data) позволяет установить связь между исходными данными и итоговым диапазоном так, что результаты будут обновляться при изменении данных. В данном случае сбросим этот флажок. | ||||

Рис. 3.10. Диалоговое окно диапазонов

Рис. 3.11. Диалоговое окно Консолидация
ШагЗ |
Нажатие кнопки ОК приводит к построению итоговой таблицы (рис. 3.12). В методе Consolidate за исходные диапазоны отвечает аргумент Sources, за способ консолидации данных — аргумент Function, за установку флажков подписи верхней строки (Top Row), значения левого столбца (Left Column) и Создавать связи с исходными данными (Create Links to Source Data) — аргументы TopRow, LeftColumn и CreateLinks. Подытожим все присвоения значений аргументов для рассмотренного примера: Range ( "Al : D4 " ) . Consolidate_ Sources :=Ar r ay (" ' [Книга1] 1998 ' ! R1C1 : R4C4", " ' [Книга2] 1999' !R1C1:R4C4") , Function :=xlSum, TopRow: =True, Left Column :=True, CreateLinks :=False |
||

Рис. 3.12. Результат консолидации
Метод DataSeries
Метод DataSeries (прогрессия) создает профессии. Вручную метод DataSeries выполняется с помощью команды Правка, Заполнить, Прогрессия (Edit, Fill, Series).
Синтаксис:
Объект.DataSeries(rowcol, type, date, step, stop, trend)
Аргументы:
|
Объект |
Диапазон с начальными данными прогрессии. Метод DataSeries позволяет одновременно строить несколько однотипных профессий с одинаковым шагом, но различными начальными элементами | ||||
|
rowcol |
Задает, вводятся профессии по строкам или столбцам. Допустимые значения: xlRows (по строкам) xlCcoluims (по столбцам) | ||||
|
type |
Определяет тип прогрессии. Допустимые значения: xlLinear (линейная) xlCrowth (геометрическая) xlChronological (даты) xlAutoFill (автозаполнение) | ||||
|
date |
Определяет тип последовательности дат, если параметр type принимает значение xlChronological. Допустимые значения: xlDay (ДНИ) xlweekday (дни недели) xlMonth (месяцы) xlYear (годы) | ||||
|
step |
Шаг изменения прогрессии. По умолчанию 1 | ||||
|
stop |
Предельное значение прогрессии. По умолчанию строится прогрессия во всем выделенном диапазоне | ||||
|
trend |
Допустимые значения: True (создается арифметическая или геометрическая прогрессия) или False (создается список) | ||||
Приведем соответствие между аргументами метода DataSeries и построением последовательности на рабочем листе командой Правка, Заполнить, Прогрессия (Edit, Fill, Series) на примере построения геометрической профессии.
|
Шаг 1 |
О В ячейку AI вводим первый член прогрессии, например 1. В методе DataSeries за начальное значение прогрессии отвечает объект, к которому применяется метод. В данном случае метод DataSeries надо применить к диапазону Range ("A1") . О Выберите команду Правка, Заполнить, Прогрессия (Edit, Fill, Series), которая приведет к появлению диалогового окна Прогрессия (Series) (рис. 3.1). | ||||

Рис. 3.1. Диалоговое окно Прогрессия
|
Шаг 2 |
В диалоговом окне Прогрессия (Series) в группе Расположение (Series in) выберите, например, переключатель по строкам (Rows), т. к. будем строить геометрическую профессию в первой строке. В группе Тип (Туре) выберите переключатель геометрическая (Growth) В поле Шаг введите например, 1.2, а в поле Предельное значение (Stop value) - 3, т. е. геометрическая прогрессия будет строиться с шагом 1.2 до тех пор, пока ее члены не достигнут значения 3. Нажатие кнопки ОК приводит к построению требуемой профессии (рис. 3.2). В методе DataSeries за расположение профессии отвечает аргумент rowcoi. В данном случае ему надо присвоить значение xiRows. За тип прогрессии отвечает аргумент type, которому присвоим значение xiGrowth. За шаг и предельное значение отвечают аргументы step и stop, которым присвоим 1.2 и з соответственно. Таким образом, имеем: Range ( "А1" ). DataSeries Rowcol : =xlRows , Type : =xlGrowth, Step:=1.2, Stop:=3 | ||||

Рис. З.2. Результат построения геометрической прогрессии
Метод Find
Метод Find (найти) используется для поиска ячейки, содержащей специфицированную информацию. Если метод Find не находит подходящей ячейки, он возвращает значение Nothing. Вручную метод Find вызывается командой Правка, Найти (Edit, Find).
Синтаксис:
Объект.Find(what, after, lookln, lookAt, searchOrder, searchDirection, matchCase, matchByte)
Аргументы:
| Объект | Диапазон, где производится поиск | ||||
| what | Элемент, который ищется | ||||
| after | Первая ячейка, после которой производится поиск. Если аргумент опущен, то поиск производится во всем диапазоне | ||||
| lookln | Область поиска. Допустимые значения: xlFormulas (формулы) xlValues (значения) xlNotes (примечания) | ||||
| LookAt | Допустимые значения:
xlwhoie (ячейки целиком) xlPart (ячейки частично) | ||||
| searchDirection | Направление поиска. Допустимые значения:
xlNext (к концу диапазона) xl Previous (к началу) | ||||
| searchOrder | Допустимые значения:
xlByRows (искать по строчкам) xlByCoiumns (искать по столбцам) | ||||
Как отмечалось выше, вручную метод Find вызывается командой Правка, Найти (Edit, Find), а значения его аргументов соответствуют заполнению диалогового окна Найти (Find), отображаемого на экране посредством выбора команды Правка, Найти (Edit, Find) (рис. 3.13).

Рис. 3.13. Диалоговое окно Найти Методы FindNext и FindPrevious используются для повторения поиска.
Метод GoalSeek
Метод GoalSeek (подбор параметра) подбирает значение параметра (неизвестной величины), являющееся решением уравнения с одной переменной. Предполагается, что уравнение приведено к виду: правая часть является постоянной, не зависящей от параметра, который входит только в левую часть уравнения. Вручную метод GoalSeek выполняется с помощью команды Сервис, Подбор параметра (Tools, Goal Seek). Метод GoalSeek вычисляет корень, используя метод последовательных приближений, результат выполнения которого, вообще говоря, зависит от начального приближения. Поэтому для корректности нахождения корня надо позаботиться о корректном указании этого начального приближения.
Синтаксис:
Объект.GoalSeek(Goal, ChangingCell)
Аргументы:
|
Объект |
Ячейка, в которую введена формула, являющаяся правой частью решаемого уравнения. В этой формуле роль параметра (неизвестной величины) играет ссылка на ячейку, указанную в аргументе ChangingCell | ||||
|
Goal |
Значение левой части решаемого уравнения, не содержащей параметра | ||||
|
ChangingCell |
Ссылка на ячейку, отведенную под параметр (неизвестную величину). Значение, введенное в данную ячейку до активизации метода Goaiseek, рассматривается как начальное приближение к искомому корню | ||||
Точность, с которой находится корень и предельно допустимое число итераций, используемых для нахождения корня, устанавливается свойствами MaxChange и Maxlterations объекта Application. Например, определение корня с точностью до 0,0001 максимум за 1000 итераций устанавливается инструкцией:
With Application
.Maxlterations = 1000
.MaxChange = 0.0001
End With
Вручную эти величины устанавливаются на вкладке Вычисления (Calculation) диалогового окна Параметры (Options), вызываемого командой Сервис, Параметры (Tools, Options).
Приведем соответствие между аргументами метода Goaiseek и нахождения корня уравнения х2 = 3 на рабочем листе вручную при помощи команды Сервис, Подбор параметра (Tools, Goal Seek).
|
Шаг 1 |
Ячейку AI отведем под неизвестную. Команда Подбор параметра (Goal Seek) находит корень уравнения методом последовательных приближений, результат которого зависит от начального приближения к корню. Команда Подбор параметра (Goal Seek) воспринимает значение, первоначально введенное в ячейку AI, за начальное приближение. Будем считать, что начальное приближение к корню равно 0. Введем 0 в ячейку A1. В методе Goaiseek аргумент ChangingCell отвечает за ссылку на ячейку, отведенную под неизвестную. В данномслучае аргументу ChangingCell Присваиваем Range ("A1") . Ячейку А2 отведем под левую часть уравнения. При решении уравнения с помощью команды Подбор параметра (Goal Seek) уравнение надо преобразовать к такому виду, чтобы в правой его части содержалась только постоянная, не зависящая от неизвестной, которая должна входить только в его правую часть. В данном случае в ячейку А2 введем формулу =А1Л2 (рис. 3.14). В методе Goaiseek диапазон, к которому применяется метод, отвечает за ссылку на ячейку, отведенную под левую часть уравнения, содержащую неизвестную. В данном случае метод GoalSeek применяется к диапазону Range ("A2") . | ||||

Рис. 3.14. Ввод данных на рабочем листе при решении нелинейного уравнения
Шаг 2 |
Выберите команду Сервис, Подбор параметра (Tools, Goal Seek). В появившемся диалоговом окне Подбор параметра (Goal Seek) (рис. 3.15) В поле Установить в ячейке (Set cell) введите ссылку на ячейку А2 В поле Изменяя значение ячейки (By changing cell) — ссылку на ячейку A1 В поле значение введите 3. В поле Значение (То value) вводится величина правой части уравнения. В методе Goaiseek аргумент Goal отвечает за правую часть уравнения. В данном случае присвоим аргументу Goal значение 3. Таким образом, имеем": Range ("A2") .GoalSeek Goal:=3, ChangingCell := Range ("A1") |
||

Рис. 3.15. Диалоговое окно Подбор параметра
Шаг3 |
Нажатие кнопки OK вызовет выполнение команды Подбор параметра (GoalSeek), результат расчета которой будет помещен в ячейки A1 (значение корня, в данном случае 1.731856) и А2 (значение левой части уравнения при найденном значении корня, в данном случае оно равно 2 .999325) (рис. 3.16). В силу того, что решение находится приближенно с указанной точностью, в ячейке А2 получилось 2.999325, а не ровно 3. Увеличивая точность, можно найти лучшее приближение к корню. |
||

Рис. 3.16. Результат вычислений команды Подбор параметра
Метод Sort
Сортировка позволяет выстраивать данные в лексикографическом порядке по возрастанию или убыванию. Метод Sort осуществляет сортировку строк списков и баз данных, а также столбцов рабочих листов с учетом до трех критериев, по которым производится сортировка. Сортировка данных вручную совершается с использованием команды Данные, Сортировка (Data, Sort). .
Синтаксис:
Объект.Sort(keyl, orderl, key2, order2, key3, order3, header, orderCus-tom,
matchCase, orientation)
Аргументы:
|
Объект |
Диапазон, который будет сортироваться | ||||
|
keyl |
Ссылка на первое упорядочиваемое поле | ||||
|
orderl |
Задает порядок упорядочивания. Допустимые значения: xlAscending (возрастающий порядок) xlDescending (убывающий порядок) | ||||
|
key2 |
Ссылка на второе упорядочиваемое поле | ||||
|
order2 |
Задает порядок упорядочивания. Допустимые значения: xlAscending (возрастающий порядок) xlDescending (убывающий порядок) | ||||
|
key3 |
Ссылка на второе упорядочиваемое поле | ||||
|
order3 |
Задает порядок упорядочивания. Допустимые значения: xlAscending (возрастающий порядок), xlDescending (убывающий Порядок) | ||||
|
header |
Допустимые значения: xlYes (первая строка диапазона содержит заголовок, который не сортируется) xiNo (первая строка диапазона не содержит заголовок, по умолчанию считается данное значение) xlGuess (Excel решает, имеется ли заголовок) | ||||
|
orderCustom |
Пользовательский порядок сортировки. По умолчанию используется Normal | ||||
|
matchCase |
Допустимые значения: True (учитываются регистры) и False (регистры не учитываются) | ||||
|
orientation |
Допустимые значения: О xlTopToBottom (сортировка осуществляется сверху вниз, т. е. по строкам), П xlLeftToRight (слева направо, т. е. по столбцам) | ||||
Например, диапазон А1:С20 рабочего листа лист! сортируется следующей командой в порядке возрастания так, что первоначальная сортировка происходит по первому столбцу этого диапазона, а второстепенная — по второму.
Worksheets("Лист").Range("Al:C20").Sort keyl:=Worksheets("Sheetl").Range("Al"), key2:=Worksheets("Sheetl").Range("Bl")
Приведем соответствие между аргументами метода Sort и сортировкой данных на рабочем листе вручную при помощи команды Данные, Сортировка (Data, Sort).
Шаг 1 |
Выделяем диапазон A1:G13, содержащий записи базы данных о туристах, которые должны быть отсортированы (рис. 3.17). В методе Sort за диапазон с записями, подлежащими сортировке, отвечает объект, к которому применяется метод. В данном случае метод sort надо применить к диапазону Range ("A1 :G13") . |
||

Рис. 3.17. Сортируемые списки
Шаг 2 |
Выберем команду Данные, Сортировка (Data, Sort). В результате появится диалоговое окно Сортировка диапазона (Sort) (рис. 3.18). |
||
Используя это окно, можно установить до трех критериев, по которым производится сортировка. Выбор в списках Сортировать по (Sort by), Затем по (Then by) и впоследнюю очередь по (Then by) определяют поля, используемые для фильтрации списка. Переключатели по возрастанию (Ascending) и по убыванию (Descending), расположенные рядом с каждым раскрывающимся списком, определяют порядок сортировки. Записи для идентификации полей, выводимые в раскрывающихся списках, определяются группой Идентифицировать поля по (My list has). Если в этой группе выбран переключатель подписям (первая строка диапазона) (Header row), то в раскрывающихся списках выводятся тексты из первых строк диапазонов. Если выбран переключатель обозначениям столбцов листа (No header row), то выводятся названия столбцов. Например, отсортируем базу данных о туристах в порядке возрастания полей, выбранных в качестве критериев сортировки, установив первоначальным критерием поле направление тура, вторичным — оплачено. Сортировку по третьему критерию производить не будем. Так как был выбран диапазон A1 : G13, содержащий названия полей, то для идентификации полей выберем в группе Идентифицировать поля по (My list has) переключатель подписям (первая строка диапазона) (Header row). В методе Sort за выбор поля, по которому производится первоначальная сортировка, отвечает аргумент key1. В данном случае для выбора поля направление тура аргументу key1 надо присвоить значение Range ("D2") . Порядок сортировки по первому критерию устанавливается аргументом Orderi. В данном случае сортируем по возрастанию, поэтому аргументу Order1присваиваем xlAscending. Вторичная сортировка происходит по полю Оплачено по возрастанию, поэтому аргументам key2 и Order2 присваиваем Range ("E2") и xiAscending соответственно. Переменной, отвечающей за идентификацию полей, является Header. В данном случае в группе Идентифицировать поля по (My list has) выбран переключатель подписям (первая строка диапазона) (Header row), поэтому переменной Header присвоим значение xiYes. Таким образом, имеем: Range ( "Al : G13 " ) . Sort Key1i : =Range ("02") , Order1 : =xlAscending, Key2:=Range("E2") , Order2:=xlAscending, Header:= xlYes |
|||
ШагЗ |
Нажатие кнопки OK приведет к сортировке записей по указанным критериям (рис. 3.19). |
||

Рис. 3.18. Диалоговое окно Сортировка диапазона

Рис. 3.19. Результат сортировки
Метод Subtotal
Метод Subtotal добавляет промежуточные итоги в список данных, основываясь на изменениях в определенных полях данных. Промежуточные итоги позволяют обобщить данные. Метод Subtotal автоматически вставляет строки с промежуточными итогами, в которые введены формулы для подсчета итогов. Необходимо, чтобы до активизации этого метода данные были правильно отсортированы. В противном случае этот метод может привести к неверному выводу промежуточных итогов. Вручную метод subtotal вызывается командой Данные, Промежуточные итоги (Data, Subtotal).
Синтаксис:
Объект.Subtotal(GroupBy, Function, TotalList, Replace, PageBreaks, SummaryBelowData)
Аргументы:
|
Объект |
Диапазон, для которого подводятся промежуточные итоги | ||||
|
GroupBy |
Номер поля, по которому вычисляются промежуточные итоги | ||||
|
Function |
Определяет функцию, по которой производится подсчет промежуточных итогов. Допустимые значения: xlAverage (среднее) xlcount (количество значений) xlCountNums (количество чисел) xlMax (максимум) xlWin (минимум) xlProduct (произведение) xlStoev (несмещенное отклонение) xlStoevp (смещенное отклонение) xlSum (сумма) xlVar (несмещенная дисперсия) xlVarP (смещенная дисперсия) | ||||
|
TotalList |
Массив целых чисел с номерами полей, по которым вычисляются промежуточные итоги, | ||||
|
Replace |
Допустимые значения: True (существующие промежуточные итоги будут замещены) и False (в противном случае) | ||||
|
PageBreaks |
Допустимые значения: True (после каждой группы будет вставлено по символу разрыва страницы) и False (в противном случае) | ||||
|
SummaryBelowData |
Определяет местоположение для вывода промежуточных итогов. Допустимые значения: П xlSummaryAbove (промежуточные итоги будут выведены над данными) П и xlSummaryBeiow (промежуточные итоги будут выведены под данными) | ||||
Основным методом, связанным с Subtotal, ывляется метод RemoveSubtotal, удаляющий промежуточные итоги с рабочего листа. Метод RemoveSubtotal применяется к объекту Range.
Приведем соответствие между аргументами метода subtotal и подведением промежуточных итогов на рабочем листе вручную при помощи команды Данные, Промежуточные итоги (Data, Subtotal) на примере подсчета продаж компьютеров по месяцам и нахождения средних объемов продаж (рис. 3.20).

Рис. 3.20. Отчет о продажах компьютеров
Шаг 1 |
Выделим ячейки списка, в данном случае диапазон A1:C16. Выберем команду Данные, Промежуточные итоги (Data, Subtotal). На экране отобразится диалоговое окно Промежуточные итоги (Subtotal) (рис. 3.21). |
||

Рис. 3.21. Диалоговое окно Промежуточные итоги

Рис. 3.22. Результат выполнения команды Промежуточные итоги
Шаг 2 |
В диалоговом окне Промежуточные итоги (Subtotal): Раскрывающийся список При каждом изменении в (Ateach change) устанавливает, по какому столбцу группируются данные. В данном случае выберем компьютер. Раскрывающийся список Операция (Use function) устанавливает операцию, выполняемую над данными. Выберем Сумма (Sum). Список Добавить итоги по (Add subtotal to) устанавливает данные, которые участвуют в расчетах. В данном случае выберем Количество. Флажок Заменить текущие итоги (Replace current subtotals) определяет, надо ли заменить старые промежуточные итоги на вновь созданные. Сбросим этот флажок. Флажок Конец страницы между группами (Page break between groups) определяет, надо ли вставлять символ конца страницы после каждой группы, для которой подводятся промежуточные итоги. Сбросим этот флажок. Флажок Итоги под данными (Summary below data) определяет расположение промежуточных итогов под или над данными, по которым подводятся итоги. Расположим их под данными и поэтому установим флажок Итоги под данными (Summary below data). |
||
ШагЗ |
Нажмем кнопку ОК в диалоговом окне Промежуточные итоги (Subtotal), что приведет к созданию промежуточных итогов на рабочем листе по выделенному диапазону данных (рис. 3.22). На VBA тот же результат достигается применением следующих инструкций: Range("Al:C16") .Select Selection. Subtotal GroupBy:=l, Function : =xlSum, TotalList:=Array (3) , Replace :=False, PageBreaks:=False, SuramaryBelowData : =True |
||
Шаг 4 |
Добавим показатель средней реализации компьютеров по месяцам к уже найденным объемам их реализации. С этой целью выделим ячейки списка с данными и уже подведенными ранее итогами, в данном случае диапазон AI :С20. Выберем команду Данные, Промежуточные итоги (Data, Subtotal). На экране отобразится диалоговое окно Промежуточные итоги (Subtotal). В этом диалоговом окне: В раскрывающемся списке При каждом изменении в (At each change) выберем компьютер. В раскрывающемся списке Операция (Use function) выберем Среднее (Average). В списке Добавить итоги по (Add subtotal) установим флажок Количество. Сбросим флажок Заменить текущие итоги (Replace current subtotals). Сбросим флажок Конец страницы между группами (Page break between groups). Установим флажок Итоги под данными (Summary below data). |
||
Шаг 5 |
Нажмем кнопку OK в диалоговом окне Промежуточные итоги (Subtotal), что приведет к добавлению показателя средней реализации компьютеров по месяцам к уже существующим промежуточным итогам на рабочем листе (рис. 3.23). На VBA тот же результат достигается применением следующих инструкций: Range ("A1:C20") .Select Selection. Subtotal GroupBy:=l, Function: =xlAverage, TotalList:=Array (3) , Replace : =False, PageBreaks : =False, SummaryBelowData : =True |
||
Шаг 6 |
Вместе с промежуточными итогами метод Subtotal создает структуру, которая позволяет управлять отображением детализации таблицы. Управляющими элементами структуры являются кнопки, отображаемые на левой стороне рабочего листа с номерами уровней иерархии, и кнопки, помеченные знаками <+> и <— >. Нажатие на кнопку <+> или <— > позволяет отобразить или скрыть детализацию данного элемента структуры, а на кнопки с номером уровня — детализацию целого уровня. Отобразим, например, только промежуточные итоги без их детализации. Для этого надо нажать сначала кнопку 2, а затем 3 (рис. 3.24). На VBA тот же результат достигается применением следующих инструкций: ActiveSheet . Outline . ShowLevels RowLevels : =2 ActiveSheet . Outline . ShowLevels RowLevels : =3 Здесь свойство Outline рабочего листа возвращает объект Outline (структура), а свойство ShowLevels объекта outline устанавливает отображаемый уровень детализации. |
||
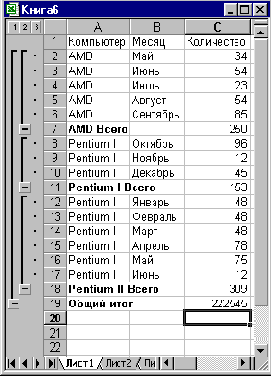
Рис. 3.23. Результат добавлению показателя средней реализации компьютеров по месяцам к уже существующим промежуточным итогам на рабочем листе
Шаг7 |
Для удаления промежуточных итогов следует выделить данные с этими итогами, выполнив команду Данные, Промежуточные итоги (Data, Subtotal) и нажать кнопку Убрать все (Remove All) в появившемся диалоговом окне Промежуточные итоги (Subtotal). На VBA тот же результат в данном примере достигается применением следующих инструкций Range ("A1:C24") .Select Selection . RemoveSubtotal |
||

Рис. 3.24. Вывод промежуточных итогов без детализации
МЕТОДЫ ОБЪЕКТА RANGE, ИСПОЛЬЗУЮЩИЕ КОМАНДЫ EXCEL
ГЛАВА 3. МЕТОДЫ ОБЪЕКТА RANGE, ИСПОЛЬЗУЮЩИЕ КОМАНДЫ EXCEL
МЕТОД DATASERIES
МЕТОД AUTOFILL
МЕТОД AUTOFILTER
МЕТОД ADVANCEDFILTER
МЕТОД CONSOLIDATE
МЕТОД FIND
МЕТОД GOALSEEK
МЕТОД SORT
МЕТОД SUBTOTAL
Глава 3.
Методы объекта Range, использующие команды Excel
В данном разделе рассматриваются методы, использующие встроенные в Excel команды. Эти методы позволяют эффективно работать с диапазоном: заполнять его элементами по образцу, сортировать, фильтровать и консолидировать данные, строить итоговую таблицу и создавать сценарии, решать нелинейное уравнение с одной неизвестной.
