Управление поиском слов
Множество слов, «известных» форт-системе, хранится в словаре в виде одного или более цепных списков словарных статей, соединенных через поле связи. Порядок поиска статей в этих списках обратен порядку их включения в словарь по времени определения: статья последнего определенного слова находится в начале списка. Такой порядок делает естественным исключение слов из словаря с помощью слова FORGET: нужный список просто усекается до соответствующего места.
Являясь самостоятельной структурой данных, список слов имеет и соответствующее определяющее слово — VOCABULARY (словарик, список слов) -->, аналогичное слову VARIABLE. Оно выделяет из входной строки очередное слово и определяет его как новый список слов, например, VOCABULARY A.
Со списками слов тесно связаны две стандартные переменные CONTEXT (контекст) и CURRENT (текущий) и слово FORTH (Форт), обозначающее список, который состоит из всех стандартных слов и включает, в частности, само это слово.
Поиск каждого введенного слова начинается в списке, на который указывает переменная CONTEXT, затем в случае неудачи просматривается список — текущее значение переменной CURRENT. Стандарт требует, чтобы последним просмотренным списком всегда был список FORTH. Исполнение слова, обозначающего список, делает его текущим значением переменной CONTEXT, т.е. первым списком, который просматривается при поиске слов.
Стандартное слово DEFINITIONS (определения)
: DEFINITIONS ( ---> ) CONTEXT @ CURRENT ! ;
устанавливает переменную CURRENT по текущему значению переменной CONTEXT, т.е. соответствующий список становится вторым на очереди для просмотра и одновременно тем списком, куда добавляются новые словарные статьи. Первоначально обе эти переменные установлены на один и тот же список FORTH. К этому состоянию приводит исполнение текста FORTH DEFINITIONS. Разумеется, в этом случае поиск слов будет состоять в одноoкрaтнoм просмотре списка слов FORTH.
Приведенное выше описание определяет порядок поиска лишь в общих чертах.
Детали стандарт оставляет на усмотрение разработчиков реализации. Обычно используется схема, приведенная на рис. 2.7. Для каждого списка в поле параметров его статьи строится заголовок «фиктивной» статьи для невозможного слова (например, состоящего из одного пробела), и представлением списка (значением переменных CONTEXT и CURRENT) служит адрес поля связи этого заголовка, т.е. адрес второго элемента в поле параметров. Сам этот элемент является входом в цепной список словарных статей, принадлежащих данному списку слов. В качестве его начального значения в момент создания списка словом VOCABULARY используется адрес поля параметров словарной статьи другого списка, который таким образом является базовым для данного (обычно это текущее значение переменной CONTEXT).
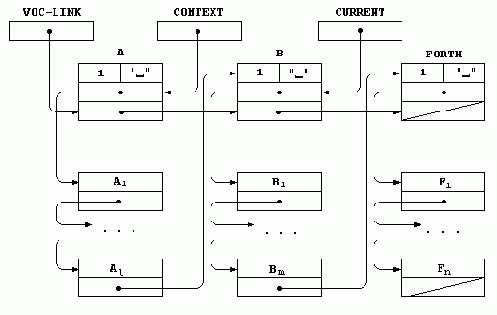
Рис. 2.7. Структура списков словарных статей
Таким образом, новый список через заголовок фиктивной статьи присоединяет к себе все слова базового списка.
В конечном счете любой список заканчивается словами списка FORTH, который уже не имеет базового. На рис. 2.7 показаны поля параметров списков A, B и FORTH. Список B является базовым для A и, в свою очередь, базируется на списке FORTH. Слова A1, ... , Al входят в список A, B1, ... , Bm — в B и F1, ... , Fn — в FORTH.
Показанный на рисунке порядок поиска слов соответствует исполнению текста B DEFINITIONS A, в результате чего сначала будут просмотрены списки A, B, FORTH, а затем B, FORTH.
Чтобы обеспечить большую гибкость в управлении порядком поиска слов и иметь возможность переопределять стандартные слова, в некоторых реализациях предусмотрено создание безбазовых списков. Это списки, создаваемые в контексте списка FORTH, для которых FORTH был бы базовым. Наличие безбазовых списков компенсируется тем, что в алгоритме поиска последним действием после просмотра списков, определяемых переменными CONTEXT и CURRENT, просматривается список FORTH, если он еще не был просмотрен через эти переменные.
Для учета всех существующих списков (что необходимо для реализации слова FORGET) в их поле параметров резервируется еще одна ячейка: через которую все эти структуры связаны в единый цепной список, начинающийся в служебной переменной VOC-LINK.
Определение слова VOCABULARY с учетом перечисленных соглашений может выглядеть так:
: VOCABULARY ( ---> ) CREATE 256 BL + , CONTEXT @ 2- , HERE VOC-LINK @ , VOC-LINK ! DOES> ( A ---> ) 2+ CONTEXT ! ;
Когда в список включается новая словарная статья, то в поле связи ее заголовка копируется значение из поля связи фиктивной статьи в поле параметров данного списка, а туда заносится адрес нового заголовка. Таким образом, можно определить слово LATEST (последний):
: LATEST ( ---> NFA ) CURRENT @ @ ;
которое возвращает адрес заголовка последней созданной словарной статьи (обычно это адрес поля имени). Через это слово становится очевидной, например, реализация слова IMMEDIATE:
: IMMEDIATE ( ---> ) LATEST C@ 128 OR LATEST С! ;
которое устанавливает в единицу признак немедленного исполнения в байте-счетчике последней созданной словарной статьи.
В соответствии с общими принципами языка Форт сам процесс поиска слова в словаре доступен программисту. Стандарт предусматривает для этого следующие слова:
' ---> CFA ['] ---> CFA (испонение) [COMPILE] ---> (КОМПИЛЯЦИЯ) FIND A ---> CFA,N / A,0
Слово ' (апостроф, читается «штрих») вводит очередное слово и ищет его в словаре, возвращая адрес поля кода найденной статьи (если слово не найдено, то это считается ошибкой).
Слово ['] имеет признак немедленного исполнения и используется внутри определений через двоеточие, образуя вместе со следующим словом единую пару: во время исполнения адрес поля кода этого слова будет положен на стек данных.
Слово [COMPILE], уже встретившееся ранее, вводит и компилирует следующее слово независимо от признака немедленного исполнения.
Наконец, слово FIND (найти) позволяет формировать образец для поиска программным путем: его параметром является адрес строки со счетчиком, которая рассматривается как имя слова. В случае успеха FIND возвращает адрес поля кода его словарной статьи и значение N, характеризующее признак немедленного исполнения: 1, если признак установлен, и -1, если отсутствует.
В случае неудачи слово FIND возвращает прежний адрес строки со счетчиком и значение 0 — сигнал о неудаче.
Разумеется, слова ' и ['] используют слово FIND :
: ' ( ---> A ) BL WORD FIND IF EXIT THEN COUNT TYPE -1 ABORT" ?" ; : ['] ( ---> ) ' COMPILE LIT , ; IMMEDIATE : [COMPILE] ( ---> ) ' , ; IMMEDIATE
которое, таким образом, является основным в определении порядка поиска слов.
В заключение рассмотрим определение стандартного слова FORGET, которое вводит очередное слово, ищет его в словаре и исключает из словаря вместе со всеми словами, определенными после него.
Служебная переменная FENCE (забор) защищает начальную часть словаря от случайного уничтожения. Она содержит адрес, отмечающий границу защищенной части (чтобы исключить слова из защищенной области нужно сначала понизить это значение):
: FORGET ( ---> ) >NAME ( NFA) DUP FENCE @ U< ABORT" ЗАЩИТА ПО FENCE" >R VOC-LINK ! ( NO:ВХОД В СПИСОК СПИСКОВ) BEGIN R@ OVER U< WHILE ( N:ЗВЕНО СВЯЗИ СПИСКА) FORTH DEFINITIONS @ DUP VOC-LINK ! ( N1:ЗВЕНО СЛЕДУЩЕГО) REPEAT ( N1:ЗВЕНО ОСТАВШЕГОСЯ СПИСКА) BEGIN DUP 4 - ( N:ЗВЕНО СВЯЗИ,L:ВХОД В СЛОВА) BEGIN N>LINK @ ( N,NFA:ОЧЕРЕДНОЕ СЛОВО) DUP R@ U< UNTIL ( N,NFA:ОСТАЮЩЕЕСЯ СЛОВО) OVER 2- ( N,NFA1,L:АДРЕС СВЯЗИ ФИКТИВНОЙ СТАТЬИ) ! @ ?DUP 0= UNTIL R> ( NFA0 ) HERE - ALLOT ;
Сначала определяется адрес статьи исключаемого слова, проверяется, что она расположена выше границы защиты, и этот адрес сохраняется на стеке возвратов. В ходе исполнения первого цикла перебираются все существующие статьи для списков слов и исключаются те, адреса которых оказались больше данного (в силу монотонного убывания адресов в цепном списке VOC-LINK цикл прекращается, как только адрес очередной статьи оказывается меньше данного). Во время исполнения второго цикла продолжается перебор оставшихся статей для списков слов, при этом в каждом списке отсекаются статьи, адреса которых больше данного (здесь опять используется монотонное убывание адресов словарных статей в пределах одного списка).В заключение указатель вершины словаря понижается до заданного адреса, тем самым освобождая память в словаре. Перед началом описанных действий переменные CONTEXT и CURRENT устанавливаются на список FORTH, чтобы их значение было осмыслено во все время дальнейшей работы.
